// ========================================================================== //
//
// Scheme 1: Entity as row
// Cache: Bit-Or and bit-And of all entity component masks
//
// ========================================================================== //
// ******** Iteration - Per page ******** //
Component... Components;
Component... Include;
Component... Exclude;
const auto include = ComponentFilter<Include...>();
const auto exclude = ComponentFilter<Exclude...>();
// If the bit-or of all entities doesn't match, no single entity will have the
// requested combination of include components
// two ops * (sizeof...Components / sizeof uint64_t)
if((page.bit_or & include.mask) != include.mask)
skip_page();
// If the bit-and of all entities is not zero, it means that all entities have
// some of the excluded components - which is unusual since pages are likely
// not full
// two ops * (sizeof...Components / sizeof uint64_t)
if((page.bit_and & exclude.mask) != 0)
skip_page();
// Entities are checked one-by-one - could be inefficient. init 1 op
for(int i = 0; i < ENTITY_PAGE_SIZE; ++i) // size = page size
{
// test 1 op
// Check include mask
// two ops * (sizeof...Components / sizeof uint64_t)
if((entity[i].components & include.mask) != include.mask)
continue;
// Check exclude mask
// two ops * (sizeof...Components / sizeof uint64_t)
if((entity[i].components & exclude.mask) != 0)
continue;
// Process entity...
// inc 1 op
}
// (page size = 32)
// total: 2 * (sizeof...Components / sizeof uint64_t) * 2
// + 1 + page size * (2 + (sizeof...Components / sizeof uint64_t) * 4)
// = 4 * sizeof...Components / 8 + 1 + page size * 2
// + page size * (sizeof...Components / sizeof uint64_t) * 4
// = 65 + 16.5 * sizeof...Components
//
// assume sizeof...Components = 16
// = 329
// assume sizeof...Components = 32
// = 593
// assume sizeof...Components = 64
// = 1121
// ******** Dirty page handling - Per page modification ******** //
page.bit_or = 0; // one op
for(int i = 0; i < ENTITY_PAGE_SIZE; ++i) // size = page size. init 1 op
// two ops * (sizeof...Components / sizeof uint64_t)
// = sizeof...Components / 4 ops
page.bit_or |= entity[i].components;
// two op
if(page.bit_or == 0) // one op
release_entity_page();
page.bit_and = -1; // one op
for(int i = 0; i < ENTITY_PAGE_SIZE; ++i) // size = page size. init 1 op
// two ops * (sizeof...Components / sizeof uint64_t)
// = sizeof...Components / 4 ops
page.bit_and &= entity[i].components;
// two op
// pseudo code. size = num components
for(int i = 0; i < sizeof...Components; ++i)
{
if((page.bit_and >> i) == 0) // two ops
release_page<Components[i]>();
}
page.dirty = false;
// total: 6 + 2 * page size * (sizeof... Components / 4 + 2)
// = 6 + 2 * 32 * (sizeof... Components / 4 + 2)
// = 134 + 16 * sizeof... Components
// ******** Add component - Per component op ******** //
if(no_page<Component>())
allocate_page<Component>();
entity[i].components<Component> = 1; // one op
page.dirty = true; // one op
// total: 3
// ******** Remove component - Per component op ******** //
entity[i].components<Component> = 0; // one op
page.dirty = true; // one op
// total: 2
// ******** Create entity from archetype ******** //
Component... InitialComponents;
Archetype<InitialComponents...> archetype;
// sizeof...Components / sizeof uint64_t
entity[i].components |= archetype.mask;
// pseudo code. size = sizeof...InitialComponents
for(auto c : InitialComponents...)
{
if(no_page<c>()) // one op
allocate_page<c>();
component_page<c>[i] = archetype.value<c>(); // #op depends on C
}
page.dirty = true;
// total: 1 + sizeof...InitialComponents + num of total C fields
// + sizeof...Components / sizeof uint64_t
// ******** Delete entity ******** //
entity[i].components = 0;
page.dirty = true;
// total: 2
// ========================================================================== //
//
// Scheme 2: Component as row
// Cache: No
//
// ========================================================================== //
// ******** Iteration - Per page ******** //
Component... Components;
Component... Include;
Component... Exclude;
// bits represent index of entities have the included components
uint32_t entity_inc = -1, entity_excl = 0; // two ops
// only pay for whay you use: only check for those components you are
// interested in + early exit. more precise than bit-or of all entities.
// write more representative Component types at the front of the type list
// for more efficient filtering.
for(auto C : Include...) // pesudo code. size = sizeof... Include
{
if(page.components<C> == 0) // one op
skip_page(); // none of entities in this page have required component
entity_inc &= page.components<C>; // two ops
}
// Components scattered in different entities but no one has all the required
// components
if(entity_inc == 0) // one op
skip_page();
for(auto C : Exclude...) // pesudo code. size = sizeof... Exclude
{
if(page.components<C> == -1) // one op
skip_page(); // all of entities in this page have excluded component...
// If an entity has any of excluded components, it will not be accessed
entity_excl |= page.components<C>; // two ops
}
// Those have the required components and not have the excluded ones
uint32_t filtered = entity_inc & ~entity_excl; // three ops
if(filtered == 0) // one op
skip_page();
// use x86 istructions to iterate entities efficiently
// size = num of filtered entites :)
while(filtered) // one op
{
uint32_t tz = _tzcnt_u32(filtered); // one op
Entity &e = entities[tz];
// Process entity...
filtered = _blsr_u32(filtered); // one op
}
// total: 2 + sizeof...Include * 3 + 1 + sizeof...Exclude * 3 + 4 + num filtered entities * 3
// = 7 + sizeof...Include * 3 + sizeof...Exclude * 3 + num filtered e * 3
//
// Assume sizeof...Include = sizeof...Exclude = 8, num filtered = 32
// = 151
// Assume sizeof...Include = sizeof...Exclude = 16, num filtered = 32
// = 199
// Assume sizeof...Include = sizeof...Exclude = 32, num filtered = 32
// = 295
// ******** Dirty page handling - Per page modification ******** //
bool release_entity_page = true;
// pseudo code. size = num components
for(int i = 0; i < sizeof...Components; ++i)
{
if(page.components<Component> == 0) // three op
release_page<Components[i]>();
else
release_entity_page = false;
}
if(release_entity_page)
release_entity_page();
// total: sizeof...Components * 3 + 2
// ******** Add component - Per component op ******** //
if(no_page<c>()) // one op
allocate_page<c>();
page.components<Component> |= 1u << i; // bts
page.dirty = true;
// total: 3
// ******** Remove component - Per component op ******** //
page.components<Component> &= ~(1u << i); // btr
page.dirty = true;
// total: 3
// ******** Create entity from archetype ******** //
int num_entity; // num of entities to create
Component... InitialComponents;
Archetype<InitialComponents...> archetype;
// pseudo code. size = sizeof...InitialComponents
for(auto c : InitialComponents...)
{
page.components<c> |= 1u << i; // 1 op (bts)
if(no_page<c>()) // one op
allocate_page<c>();
component_page<c>[i] = archetype.value<c>(); // #op depends on C
}
page.dirty = true;
// total: 1 + sizeof...InitialComponents + num of total C fields
// ******** Delete entity ******** //
// pseudo code. size = num components
for(int i = 0; i < sizeof...Components; ++i)
{
page.components<Component> &= ~(1u << i); // btr
}
page.dirty = true;
// total: sizeof...Components * 3 + 1
// ========================================================================== //
//
// Disassembly
// https://godbolt.org/z/6vmsqK
//
// ========================================================================== //
unsigned set_bit(unsigned a, unsigned b)
{
unsigned ret = a | (1u << b);
return ret;
}
unsigned unset_bit(unsigned a, unsigned b)
{
unsigned ret = a & ~(1u << b);
return ret;
}
unsigned test_include(unsigned a, unsigned b)
{
unsigned ret = (a & b) != b;
return ret;
}
unsigned test_exclude(unsigned a, unsigned b)
{
unsigned ret = (a & b) != 0;
return ret;
}
unsigned test_filter(unsigned a, unsigned b)
{
unsigned ret = a & ~b;
return ret;
}
asm(R"(
set_bit(unsigned int, unsigned int):
mov eax, edi
bts eax, esi
ret
unset_bit(unsigned int, unsigned int):
mov eax, edi
btr eax, esi
ret
test_include(unsigned int, unsigned int):
and edi, esi
xor eax, eax
cmp edi, esi
setne al
ret
test_exclude(unsigned int, unsigned int):
xor eax, eax
test edi, esi
setne al
ret
test_filter(unsigned int, unsigned int):
not esi
mov eax, esi
and eax, edi
ret
)");
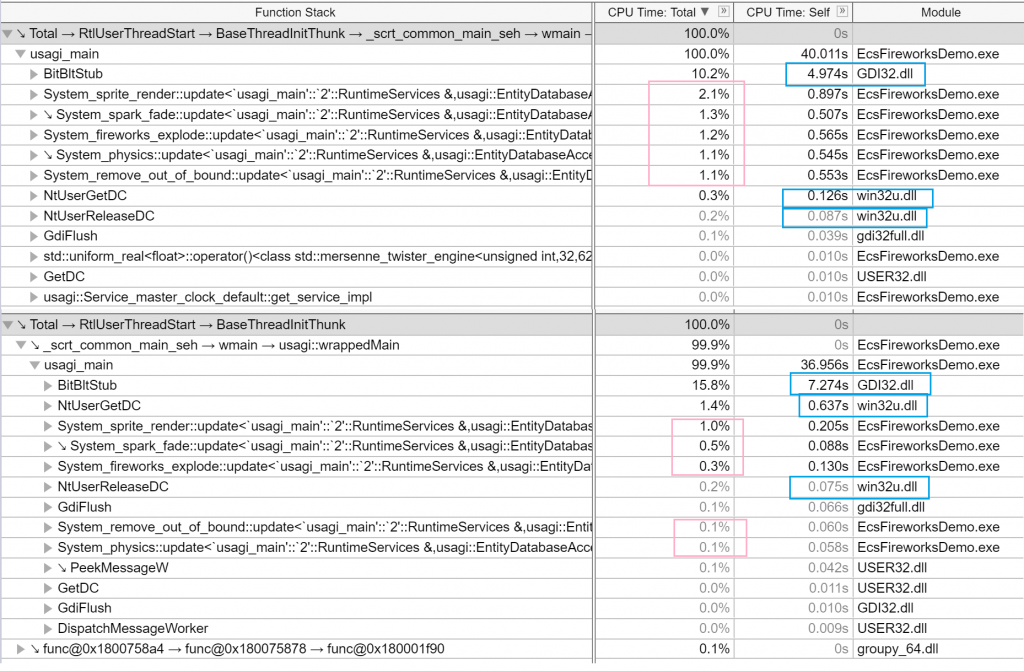
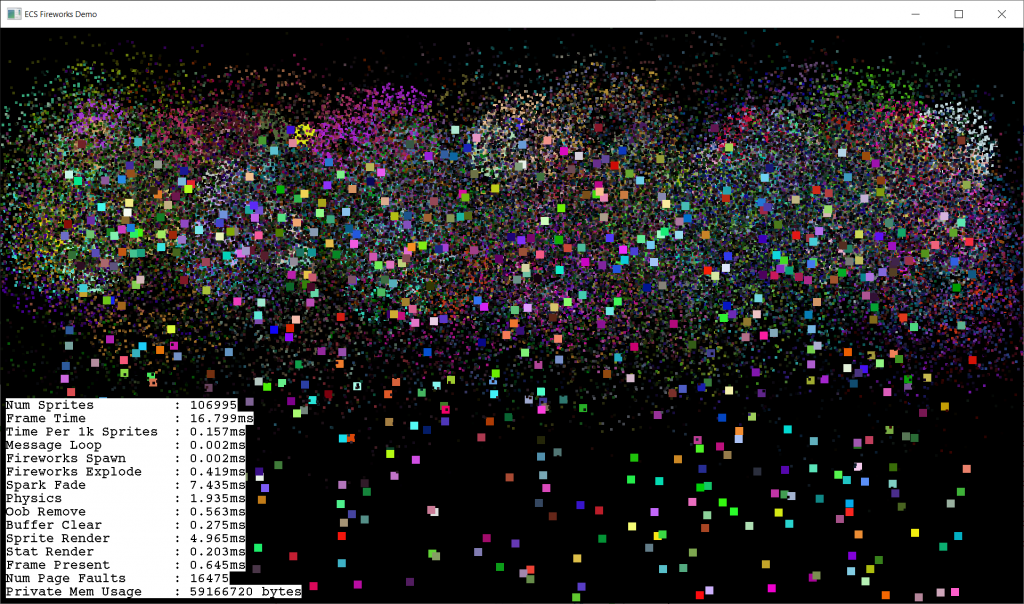
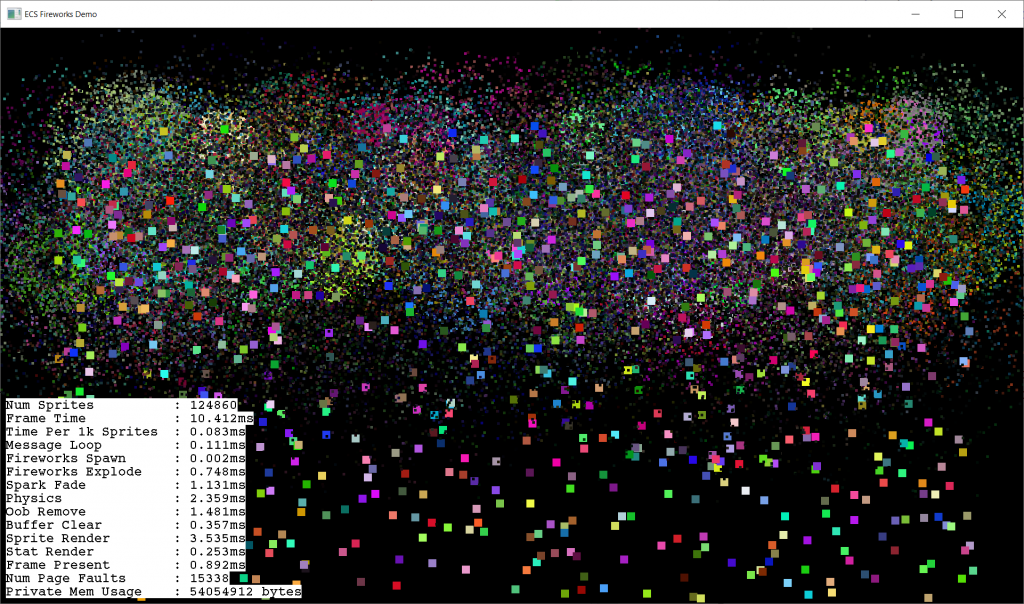
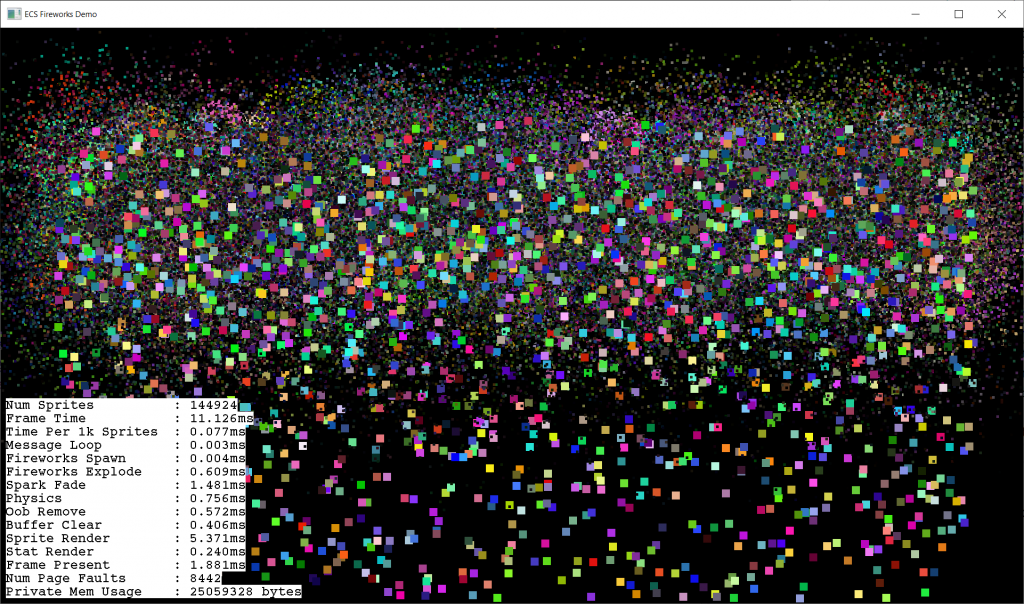
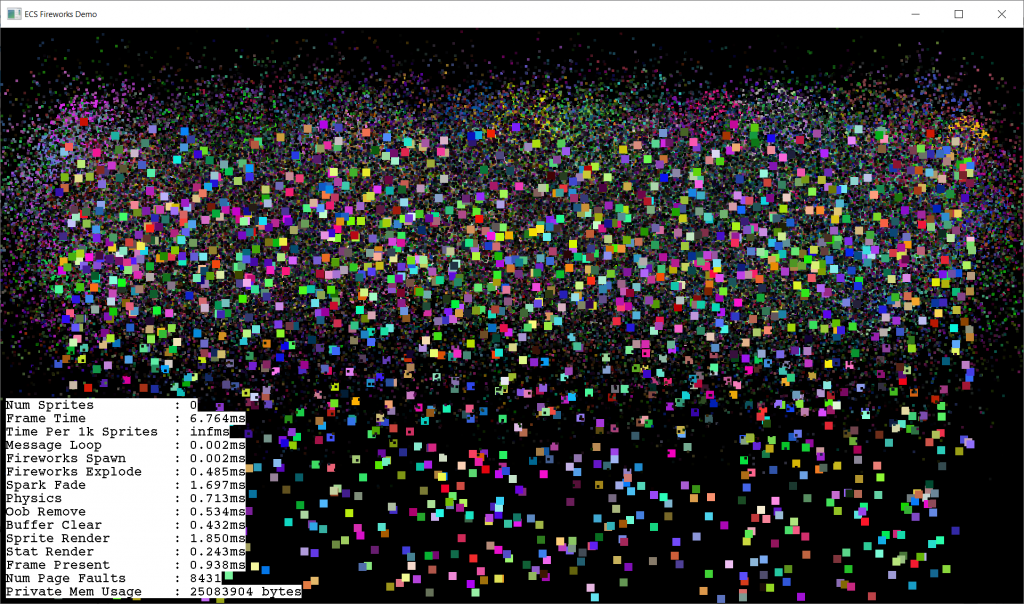
Before and after redesigning the entity pagePressure test (single thread)Spark fade & sprite render parallelizedAll parallelized with std::for_each (render is slow because of an atomic variable). CPU util ~= 50%Atomic sprite counter turned off & reduced critical section for entity creation